Static files are the new databases
In the last article, we discussed why API caching isn’t always the best caching strategy when we want to cache highly requested endpoints, which include data that is heavy to calculate. The reason behind the problem with API caching here is the “thundering herd” problem; you can read more about what it is in the previous article in the series.
Other caching methods to use
Read-through
The problem mentioned above is using the caching strategy called “Read-through” caching. This, in our case, sits between our users and our API to prevent users from hitting the API and both requesting the database, as well as not invoking a new instance of the lambda function.

Write-through
Another way to cache heavy calculations from a database is something called write-through caching. This strategy is different from the read-through strategy. The reason is that it first writes to the cache and afterwards writes the data to the database. If new data has been posted by a user in a database, it would get inserted into the cache, then the database.
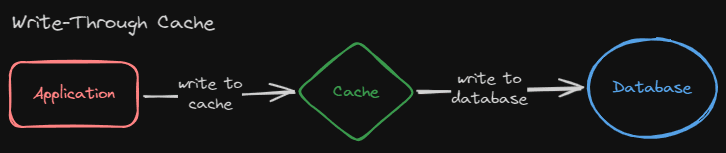
But in our case, we don’t have any users who create new entries into our database. We have a processor that processes data, calculates it, and inserts it into the database. How can we scale this so people can request this kind of data without users querying the database directly?
The golden era of static files
You have probably seen programming memes about having your database as static files or even Excel spreadsheets. Maybe it is a bad idea to use static files or Excel spreadsheets as the primary database, but not for caching the data.

The reason why static files are good for storing data is that they scale almost infinitely. One minor detail to note is that the data needs to be the same for all users. If you have set up an S3 bucket in front of a CloudFront distribution, you can utilize the scaling CDN to scale your data globally, which now gets even closer to the end user.
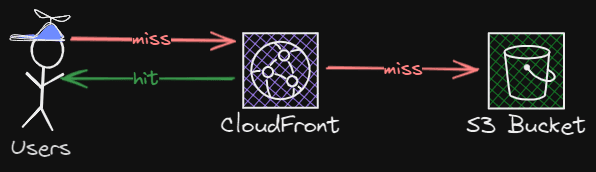
This caching strategy works perfectly in our use case because the real-time statistics data should be the same for every user and is calculated through heavy calculations, which should only happen a couple of times every other second or so.
This method would require a processor that runs on a cron job, which calculates the statistics and inserts them into the bucket, which the CDN would distribute. For our use case, we would only need the processor to run if we have an ongoing match.
Implementation of static files as a caching strategy
In our system, we need to scale the data to as many users as possible in real-time, so our users won’t miss any in-game statistics. When you want to use cache the normal way, you traditionally want to cache responses for as long as possible.
That way, you prevent the many requests from going directly to the service to fetch the data. In our system, we still want to prevent users from requesting data directly from the S3 bucket. Having the CloudFront distribution in front of it prevents requests from going directly to the S3 bucket.
When we want to update the in-game statistics, we need to invalidate the cache on the CloudFront distribution. To invalidate the cache, we say to CloudFront, that they should delete the cached versions from all of their edge nodes around the globe. Next time a user requests the updated in-game statistics, CloudFront grabs the updated version from our S3 bucket, and caches the updated version on their edge nodes, so the other users would be able to access it.
Adding origin shield, but why?
Invalidating cached files from a CloudFront distribution technically deletes the stored file on each of the edge nodes globally. After all files have been deleted from all edge nodes, CloudFront then needs to fetch the file from its origin (S3 bucket). If a lot of users are requesting the same file at the same time, but CloudFront hasn’t cached it yet, then all requests would go to the S3 bucket, which means that you could see a spike in reads on your bucket.
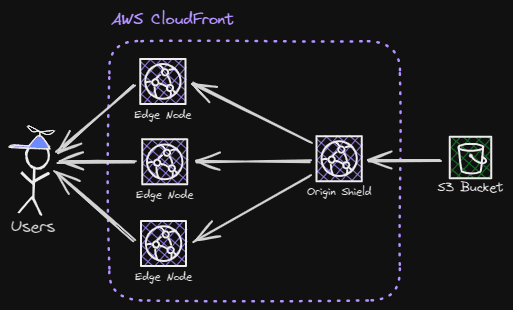
This is where the origin shield comes to save the day. This is AWS CloudFront’s own explanation of what an origin shield is:
Origin shield is an additional layer in the caching infrastructure that helps to minimize your origin’s load, improve its availability, and reduce its operating costs.
As stated above, an origin shield is an additional layer in how the CloudFront distribution caches data. The layer lies above all the edge-nodes and prevents them from reading directly from the origin (S3 bucket). Instead, the edge-nodes read from the origin-shield, which has the data lying in its cache/storage.
Other technologies used for scaling real time data
Other technologies you can use to distribute read time data to users include web sockets. Sockets run on an open TCP connection as their transport protocol, which means there’s no need for a new handshake, and data can be delivered with high performance.
You can publish events/messages to subscribers, which would then get those events. In our case, we can use this to distribute our live statistics to users who subscribed to them.
A typical web socket system/infrastructure could look something like this:
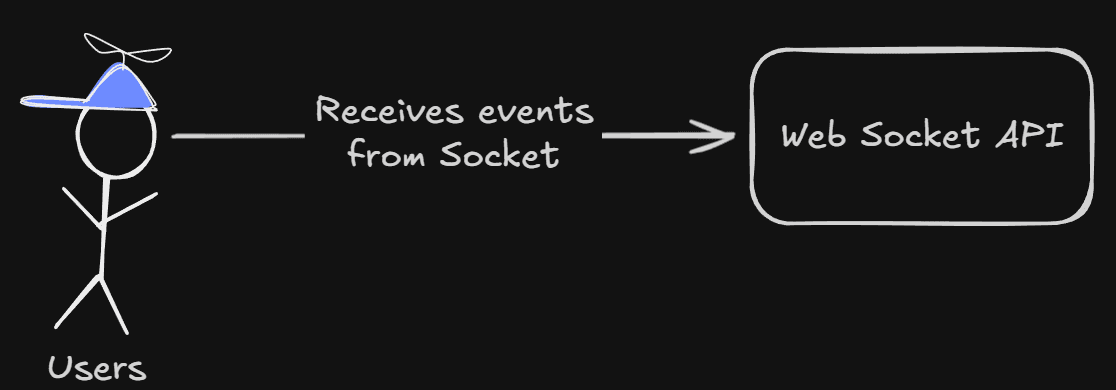
Here, the user first subscribes to the socket API, and then they receive events or messages from the socket API via the socket connection.
Usually, you would scale your APIs depending on the load. In our scenario, with our live streams, we could have between 500 and 5000 viewers. Having one server handling 5000 socket connections wouldn’t be reliable.
Although it seems pretty easy to scale an API, it’s a bit harder to scale an API when it needs some state. The state in this case is a list of all the connected clients to all our WebSocket APIs. Since each API does not know what connections the other APIs have, there is no way for it to send messages to those clients.
We can share this state between the APIs with a cluster, which is normally a database, to store all the clients. The popular JavaScript library used to manage web sockets, socket.io, has clustering built in, with some cluster adapters built in.
In our situation, we want the cluster to react to changes quickly. So it can deliver events/messages with high performance. We are using Redis in this example. With our scaled APIs and our web sockets cluster created, our infrastructure now looks like this:
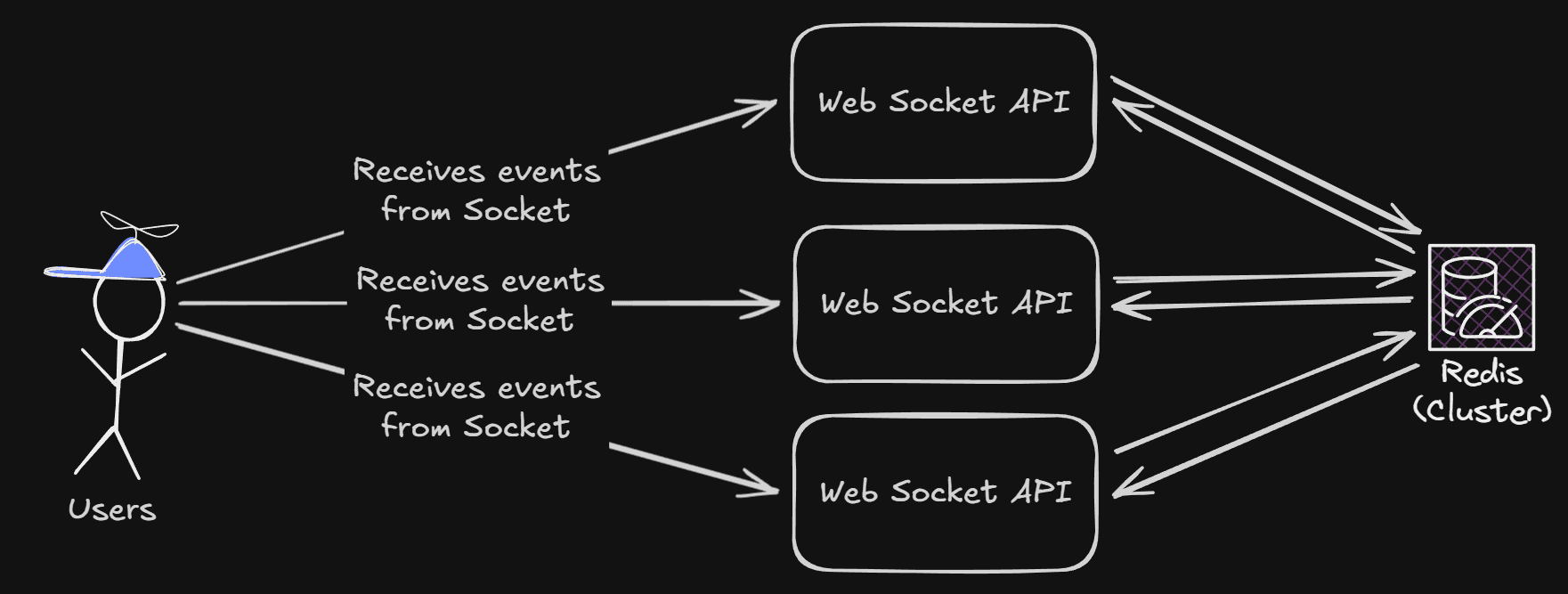
As you can see, each of the WebSocket APIs is connected to the Redis cluster, and both send and receive information about the other APIs' connections.
But why do we need a cluster if we scale our APIs
Since each of the APIs only knows about its own connections without the cluster. If we then wanted to send a message, the send (POST) request would be sent to one of the APIs, and that API would only be able to send the message to its own connections, not the other APIs’ connections.
What about server-sent-events (SSE)
You can also use server-sent-events. One of the drawbacks of SSE is that it’s not bi-directional, which means that the client can’t send messages back to the server. In the situation regarding the live stats, it doesn’t really matter. The client should only consume messages and not send anything back to the server.
Conclusion
We have gone through different methods to distribute live data to users. Each one of them has its own pros and cons. It’s always good to discuss with a broader team or other people about what you think is the best solution to serve real-time data to your users.
Some questions are good to ask yourself when trying to decide:
- How well should it scale?
- Most of the time static files are the answer
- Do we want clients to send back information?
- Web sockets is a good choice here, to prevent a lot of API calls
- Is a simple setup good enough for our use case?
- If you know API caching would be good enough, and you know you wouldn’t get a “Thundering Herd” problem. Then API caching is the simplest solution
Hopefully, this series has been useful for you to read. If you haven’t read the other articles in the series, I highly recommend reading the other 3. Those explain the problem that we have faced, and not only the solution.
I’m hoping this shared some insight on how to scale real-time data to users, problems you can face, and how to prevent them when they occur. I can at least say that my team and I have learned a lot about how to tackle it, as well as what and how to implement this in other situations.
Thanks for reading the article (maybe series). Hope you have a wonderful day ☀️